# 高可用
# 简介
对于任何一个数据库,提供安全稳定的数据存储服务永远是首要也是最重要的职责。
eZooDB不仅在各种图能力上有着突出的性能表现,在数据库的基础能力方面也提供了全方面的保障。
作为分布式的内存型图数据库,我们通过WAL、内存镜像、持久层管理等多种技术手段,确保能够应对各种面向网络、硬件、系统文件的灾难事件,并通过最小代价完成错误数据的检测、隔离与修复,保证接口层面的全图数据一致性。
# 基于节点故障的高可用
当网络发生故障、服务进程异常中断等,导致集群中某些节点不可访问时,集群将隔离故障节点,保持整体服务的正常,故障节点会进入等待状态,网络恢复后将重新加入集群,完成历史数据同步后开始提供服务。
# 测试方法
对集群节点所在机器,进行物理断网操作,然后重新连接网络,分别观察断网前后集群的响应。
# 服务响应
- 故障节点断网后,服务中断,进入等待重连状态
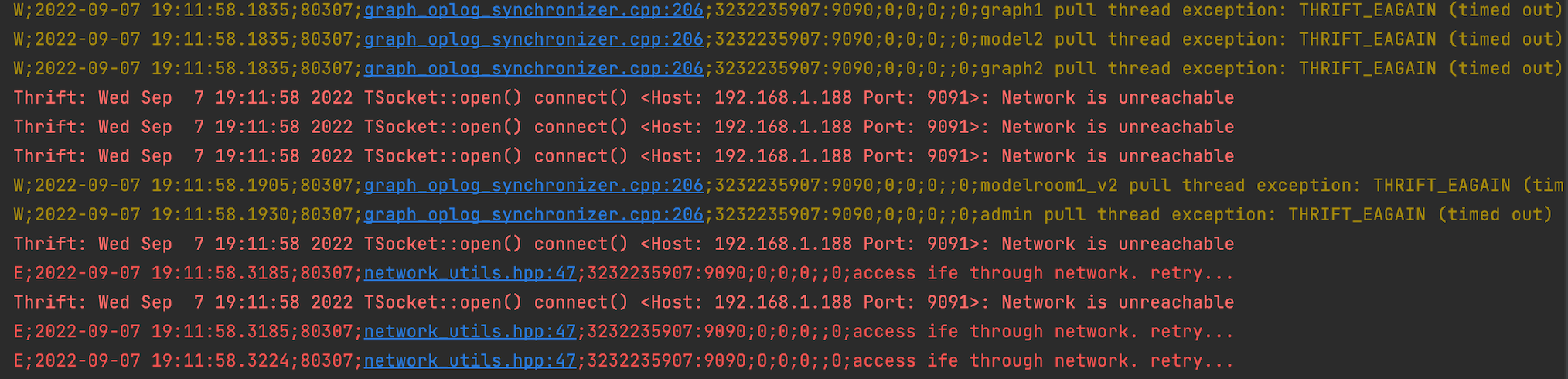
- 当故障节点为主节点时,从节点开始尝试呼叫主节点,呼叫超时后,集群将启动重新选举


- 当故障节点恢复正常访问后,自动连接并进行数据同步
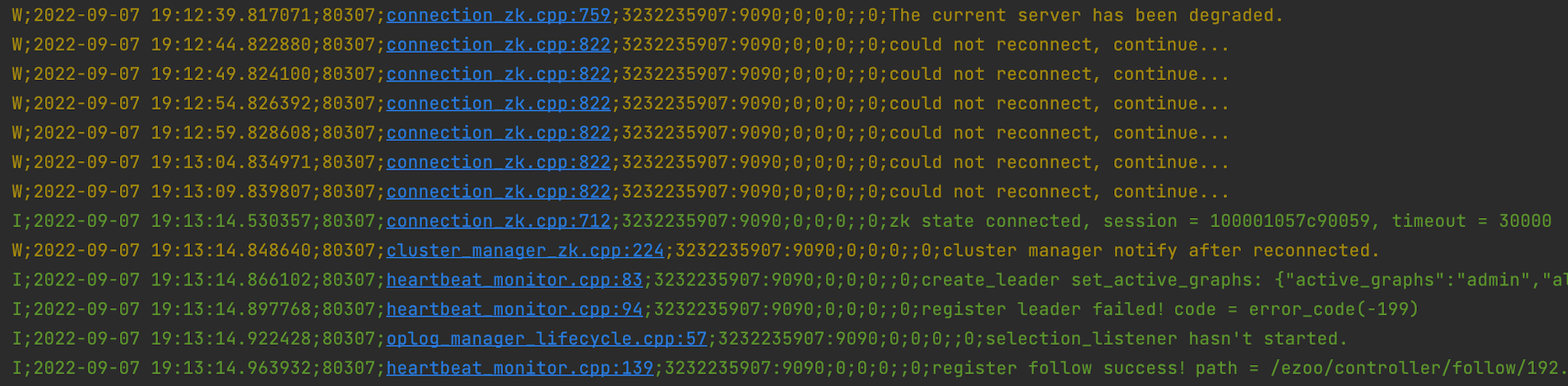
# 基于磁盘故障的高可用
当磁盘异常、或磁盘IO异常时,服务进程能够保持稳定无异常,磁盘故障恢复后,读写数据保证无错误。
# 测试方法
- 启动10并发的数据库联机压测程序,运行5分钟
- 执行命令:
echo 1 > /sys/block/sdal/device/delete,模拟磁盘故障 - 等待5分钟
- 重启服务
- 执行数据校验脚本,通过读写操作验证全图数据的正确性
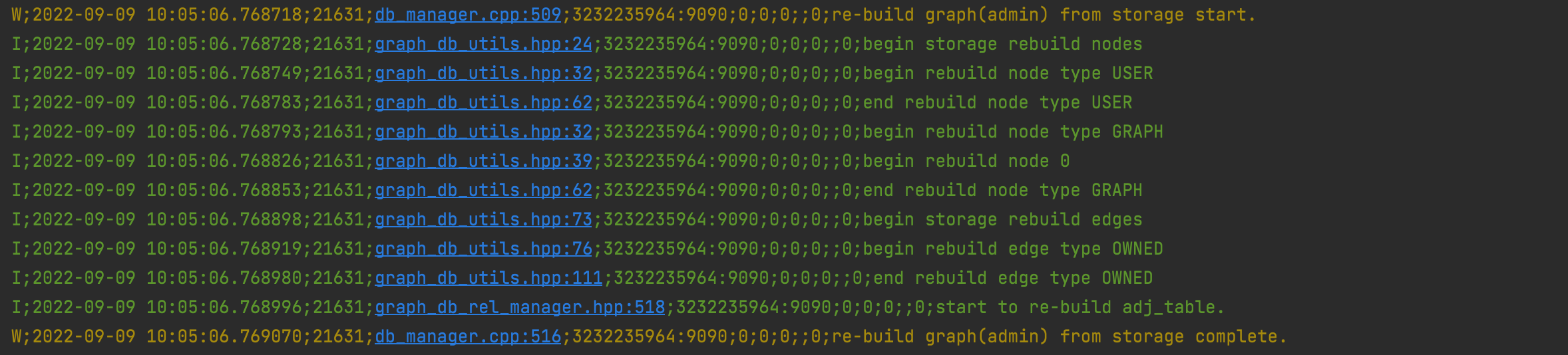
# 基于数据异常的高可用
eZooDB采用多层机制来确保数据的正确性,作为分布式内存型数据库,从应用层到底层,发生数据异常时将触发相应机制进行数据修复。
- 集群节点通过oplog、水位等信息进行一致性校验,发生异常时,将启动从主节点全量同步
- eZooDB的持久化是基于内存镜像文件与元数据文件,由于内存异常或文件错误,导致内存镜像文件损坏时,将启动基于元数据的修复
- 我们支持并鼓励用户定期备份,当发生元数据文件的损坏或丢失时,可以通过备份文件进行指定图、或全库的还原
# 测试方法
针对从集群主节点或备份文件进行修复的情况,操作以文件复制为主,基于数据异常的高可用测试,主要以基于元数据文件修复为目标。
- 删除oplog或内存镜像文件,模拟除元数据之外的数据异常
- 启动服务
- 自动进行数据校验,检测出数据异常并启动修复(rebuild),修复完成后恢复正常启动流程